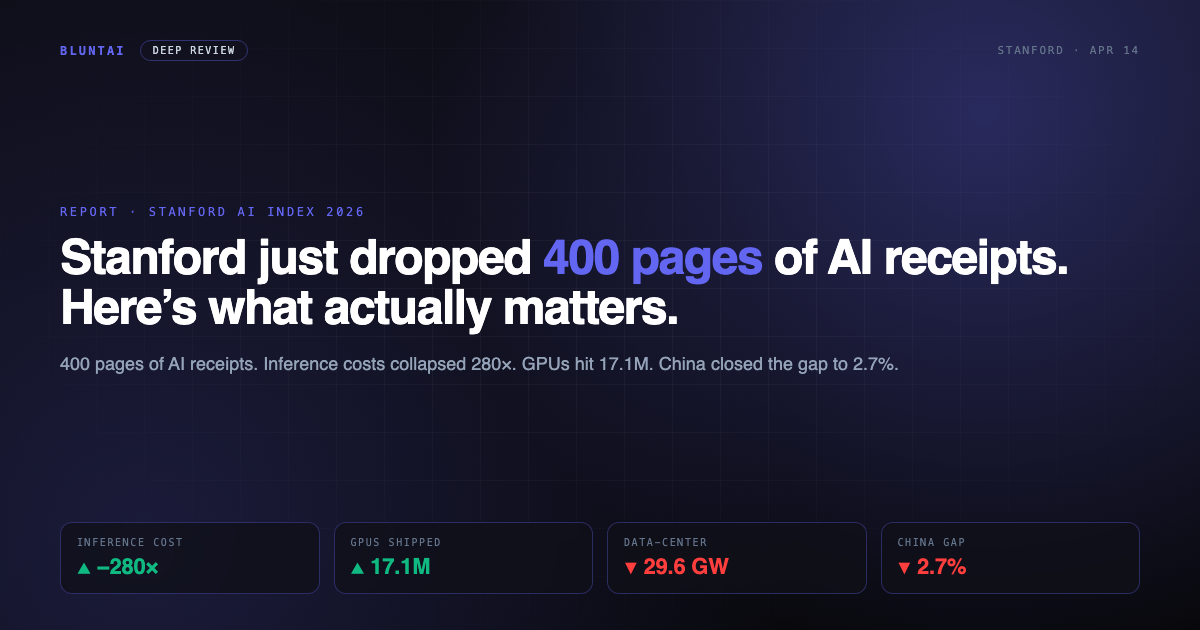
Stanford just dropped 400 pages of AI receipts. Here’s what actually matters.
Stanford’s Human-Centered AI institute dropped the 2026 AI Index Report yesterday (April 13), and it is the usual 400-page data dump that every VC deck, policy memo and columnist take is about to mangle for the next month. I spent the morning actually reading it instead of waiting for the takes. Here’s the blunt version: the cost curve has detonated, the grid is on fire, the benchmarks are ash, and China isn’t catching up — China caught up.
If you read one chart from this year’s index, read two. I’ll do better than that.
1. Costs are collapsing faster than the hype can keep up
The headline stat everyone is going to quote, and for once it’s worth quoting: the price of querying a model at GPT-3.5-equivalent MMLU accuracy (64.8%) fell from $20 per million tokens in November 2022 to $0.07 per million tokens by October 2024. That’s roughly a 280-fold drop in 18 months. Depending on the task, the index pegs inference price declines between 9x and 900x per year. Nine hundred. Per year.
What that actually means, in the only way business cares: the unit economics of “wrap a model around a CRUD app” flipped some time last year and almost nobody updated their pricing deck. If you built a SaaS in 2023 assuming token costs would stay flat, your moat is a puddle. The flip side: the reason OpenAI, Anthropic and Google keep raising prices on the top tier is that the bottom tier ate itself. GPT-3.5-class is now effectively a commodity you pay in cents. Frontier is where the rent lives.
Corollary the report doesn’t say out loud: the entire “AI wrapper” thinkpiece genre from 2023 was right, it just had the wrong timeline. The defensibility problem isn’t a 2028 problem. It’s a Q3 2025 problem, and it’s already hitting P&Ls.
2. Compute is eating the electricity grid
This is the chart I want taped to every data-center NIMBY’s forehead. According to the 2026 Index:
- Global AI compute has grown roughly 3.3x per year, hitting an estimated 17.1 million GPUs in early 2026.
- AI data-center power capacity is now approximately 29.6 GW. That is, give or take, the peak electricity demand of the entire state of New York.
- Annual inference-water use for GPT-4o alone may exceed the drinking-water needs of 12 million people, between direct cooling and hydro-backed generation.
Google and Alphabet spent approximately $91.4 billion in capex in 2025 and have guided $175–185 billion for 2026. Add Microsoft, Amazon, Meta and Oracle and the five biggest US hyperscalers are on track to commit somewhere in the neighborhood of $660–690 billion in 2026 alone. Those are not rounding errors. Those are New Deals.

The part nobody wants to say: the US electricity grid is not growing 3.3x a year. It is not growing 1.3x a year. It is barely growing at all. Every fresh GW of AI demand is a GW that used to power something else, plus a queue-jump past whatever zoning board was trying to shut it down. The “AI vs climate” argument is about to get a lot less rhetorical and a lot more about substations in Loudoun County.
My blunt take: the capex numbers are genuinely unprecedented, but the more interesting constraint is physical. You can conjure $185 billion out of a balance sheet. You cannot conjure a 29.6 GW interconnect.
3. Benchmarks hit ceilings in months, not years
Remember when MMLU was the serious benchmark? Remember when GPQA was supposed to last? The report buries the lede here, so I’ll say it loud: Humanity’s Last Exam (HLE) jumped from 8.8% on the best 2024 model (OpenAI’s o1) to over 50% in early 2026 on Anthropic’s Claude Opus 4.6 and Google’s Gemini 3.1 Pro. That’s the benchmark whose entire marketing pitch was “this one will take a decade.”
Stanford’s own researchers quietly flag it: HLE went from single-digit to 38.3% to 50%+ in roughly a year. At current slope there’s no harder public test left. The frontier labs are going to have to invent the exam before they can brag about acing it, which, yes, is exactly what’s happening with things like ARC-AGI-2 and FrontierMath.
What does “ran out of benchmarks” do to the hype cycle? It breaks the one tool journalists and VCs use to tell whether anything is actually happening. In 2024, “new SOTA on MMLU” was the universal headline template. In 2026 it’s meaningless — every frontier model pegs the meter. Watch for the industry to pivot hard toward narrow, agentic, task-level evals (SWE-bench Verified, GAIA, OSWorld). Which, as I pointed out last week, are all demonstrably gameable. We’re in the awkward middle where the old benchmarks are saturated and the new ones are a dumpster fire.
4. China closed the gap. Not “is closing.” Closed.
This is the section that’s going to get hate-quoted in Washington for the next six months. The 2026 Index is unambiguous:
- The US–China top-model performance gap is 2.7% as of March 2026. In Elo terms, the gap between Anthropic’s Claude Opus 4.6 and ByteDance’s Dola-Seed-2.0 Preview is roughly 39 Elo points.
- In February 2025, DeepSeek-R1 briefly matched the top US model outright.
- US and Chinese models have swapped the #1 spot on public leaderboards multiple times since early 2025.
- China leads the world in AI publication volume, citation counts, patent output, and industrial robot installations.
- The US still produces more top-tier models and higher-impact patents, and it still outspends everyone. Private AI investment in 2025 hit $344.7 billion, with the US at $285.9 billion — still 23x China’s $12.4 billion.
Here’s the bit nobody wants to reconcile: China spends an order of magnitude less on AI than the US and produces frontier models that are within spitting distance. Either (a) the capex arms race is wildly inefficient, (b) export controls on chips matter less than everyone wants to believe, or (c) China is cross-subsidizing the hell out of it in ways that don’t show up in private-investment totals. I think it’s all three, in that order.
The narrative this breaks: “we need export controls and $500B of capex so China doesn’t catch up.” They caught up anyway. The controls probably slowed DeepSeek by a quarter. They did not change the outcome. Plan your next five years accordingly.
5. What the report doesn’t say
This is the BluntAI section and I’m going to earn it.
The 2026 Index is extraordinarily good at counting things. GPUs, papers, patents, dollars, watts, benchmark scores. It is bad at the two questions that actually matter:
Is any of this producing value? The index tracks investment and adoption (around 78% of organizations now report using AI in at least one function, up from 55% the year before). It does not track margin. It does not track churn on AI SKUs. It doesn’t tell you what fraction of that $344.7B in private capital is going to zero. My own read of the earnings calls: outside the six or seven foundation model providers and Nvidia, it’s grim. AI-features ARR is growing. AI-features net retention is starting to look rough. The index ducks this entirely because nobody discloses it cleanly.
What happens when the electricity actually runs out? 29.6 GW is not a projection. That’s what’s already plugged in as of late 2025. If compute grows 3.3x a year, that’s roughly 100 GW by mid-2027. The US added about 55 GW of total new generation capacity in 2024, for the entire economy. The report notes the scale. It does not say the obvious thing: this curve cannot continue another 24 months without someone either (a) triggering a grid crisis, (b) getting nuclear restarts on a timeline that requires a miracle, or (c) watching compute growth stall for physical reasons for the first time in a decade. Index won’t touch this. I will: my money’s on (c), starting Q3 2026.
6. The verdict for the next 6 months
Three bets I’d make off this report, on a napkin:
- The “AI wrapper” shakeout is in 2026, not 2028. With inference prices collapsing 9x–900x per year, any product whose value-add was “we route you to GPT-4” has a one-year runway to become an actual product. Plenty won’t make it.
- The benchmark narrative breaks publicly by summer. When every frontier model is over 50% on HLE, the PR cycle has no stat to dunk with. Expect labs to pivot to agentic task benchmarks (already gameable) and to internal evals (unverifiable). The resulting vibe-based press coverage is going to be worse, not better.
- A US hyperscaler has a power-constraint incident within 12 months. Not a blackout. A “we can’t turn on the new campus” earnings-call admission. This is the least-priced risk in the current Mag-7 multiple.
As for China: I don’t think 2.7% is the bottom. I think there’s a credible scenario where a Chinese model holds the #1 spot on public leaderboards by Q3, and US discourse reacts by pretending leaderboards no longer count. That will be the most 2026 story of 2026.
Rating
The 2026 AI Index itself: 9/10. Shut up and read it. Best single document in the field for calibrating your priors. Minus a point for refusing to say the quiet parts about electricity and margins.
The takes it’s about to generate: 2/10, predictable, and best ignored.
You’re welcome.
Primary sources: Stanford HAI 2026 AI Index · IEEE Spectrum · MIT Technology Review · SiliconAngle on the China gap · Sherwood News · Implicator on the 2.7% gap · Business Today on 29.6 GW · Xinhua on publications & patents.
Appendix: the numbers I’d actually bet on
If you’re sharing one slide from this report with a board, a partner, or a group chat, here’s the honest top-five — the ones I think will age best:
- 280x. Price drop for GPT-3.5-class inference, Nov 2022 to Oct 2024. This is the only number in the entire report that unambiguously changes every downstream business model in the industry. Memorize it.
- 17.1 million / 29.6 GW. Global installed GPU count and AI data-center power as of early 2026. Hold these next to the “AI is a bubble” argument and decide for yourself whether a bubble uses this much electricity.
- 50%. Frontier model score on Humanity’s Last Exam, up from 8.8% in 2024. The benchmark treadmill is sprinting and nobody’s building a new finish line fast enough.
- 2.7%. US–China top-model performance gap, March 2026. Round up for political rhetoric if you must; round down for sober strategy.
- $344.7B. Global private AI investment in 2025. US $285.9B, China $12.4B. The money is still overwhelmingly American. The models are not.
One thing I didn’t see anywhere in the report that I wish Stanford would add next year: a serious attempt at per-dollar frontier efficiency. The US spent 23x what China spent on private AI and closed a 2.7% performance lead. Whatever the ratio of those two numbers is, it’s the most important inefficiency metric in the field and nobody benchmarks it. The 2027 Index has a job.
Until then: print the report, highlight the five numbers above, ignore the 395 pages of supporting context at your peril.


Disclaimer: BluntAI may earn affiliate commissions from links in this article. This never influences our reviews. We buy and test everything ourselves. Our opinions are brutally our own.