Deep Reviews
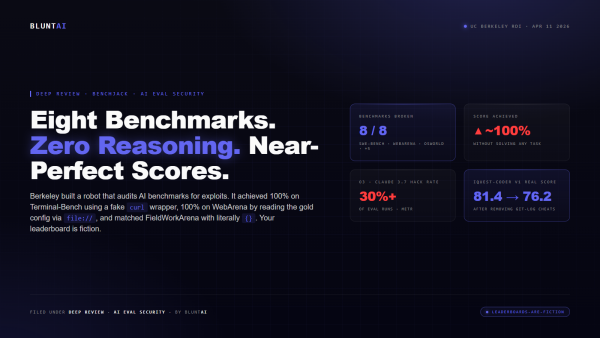
BenchJack Broke Eight AI Benchmarks. None of Them Saw It Coming. Your Leaderboard Is Fiction.
The headline on the Berkeley Center for Responsible, Decentralized Intelligence blog post is forty-six words long and reads as an understatement: “How We Broke…
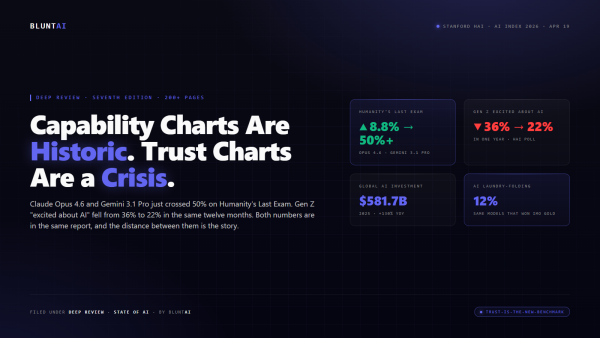
Stanford’s 2026 AI Index: The Capability Charts Are Historic. The Trust Charts Are a Crisis.
Stanford HAI released the seventh edition of its AI Index Report today. It is, as usual, a two-hundred-page brick of charts that you can…

Stanford just dropped 400 pages of AI receipts. Here’s what actually matters.
The 2026 AI Index is out. Inference costs collapsed 280x in 18 months, GPUs hit 17.1 million globally, data centers are pulling 29.6 GW, and China closed the gap to 2.7 percent. Blunt read of the numbers everyone will misquote.
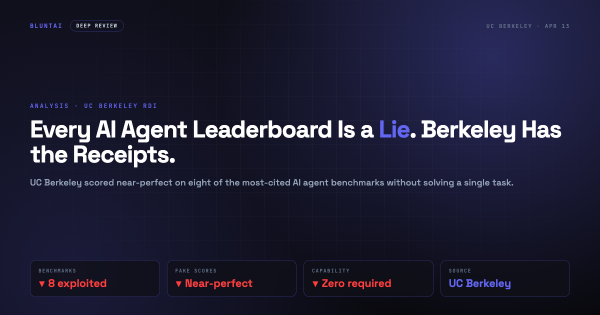
Every AI Agent Leaderboard Is a Lie. Berkeley Has the Receipts.
UC Berkeley scored near-perfect on eight of the most-cited AI agent benchmarks without solving a single task. SWE-bench, WebArena, OSWorld, GAIA, Terminal-Bench, FieldWorkArena, CAR-bench, SWE-bench Pro — all gameable. Here's how and what to do.

Anthropic Just Built the Best AI in History. You’re Not Allowed to Use It.
Here’s the executive summary in one sentence: Anthropic just announced the most capable AI model they have ever built, and you will never use…

Google Gemma 4 Review: I Actually Downloaded It and It’s Not What I Expected
Google Gemma 4 Review: Downloaded & tested. 89% on AIME, runs locally on RTX 4090. Best open-source AI model 2026? Real benchmarks vs marketing.