
DeepSeek V4 Came In 89× Cheaper Than Claude And Open-Sourced The Whole Thing
April 24, 2026 was the day Silicon Valley’s pricing strategy stopped making sense. OpenAI used the morning to launch GPT-5.5 — repackaged as the “super app,” available through ChatGPT for whatever subscription tier you happen to be paying. DeepSeek used the same morning to drop V4-Pro and V4-Flash on Hugging Face under MIT license, with open weights, a one-million-token context window as standard, and an output price of $0.28 per million tokens on the smaller model.
That last number is not a typo and the comparison is not subtle. Claude Opus 4.6 charges $25 per million output tokens. Run ten million tokens through V4-Flash and you spend $2.80. Run the same workload through Claude and you spend $250. 89× cheaper, available to download, MIT-licensed. Same day, same hour, completely different physics.
I want to walk through what was actually released, because the headline is loud but the details are louder.
What dropped

DeepSeek V4 is a two-model family, both Mixture-of-Experts, both open-weight on Hugging Face, both shipping with the long-context architecture as the default rather than as an afterthought.
V4-Pro is the headliner: 1.6 trillion total parameters with 49 billion activated per token. That makes it the largest open-weight model that exists right now — bigger than Moonshot’s Kimi K 2.6 (1.1T), more than double DeepSeek’s own V3.2. The architecture is built around 1M-token native context (not retrieved, not slid, not bolted on) and includes a dual Thinking / Non-Thinking mode toggle similar to Claude’s extended thinking.
V4-Flash is the smaller sibling: 284 billion total, 13 billion active. It’s still bigger than most flagship Western open-weight models and exposes the same 1M context window. Both come with a thin API wrapper at api.deepseek.com if you don’t want to host them yourself.
The license is MIT. There is no “research only” clause, no “non-commercial” clause, no commercial-use threshold above which you have to email a sales team. You download the weights, you run them, you ship a product. That is the entire deal.
The benchmarks

DeepSeek’s release was timed for the GPT-5.5 launch on purpose, and the benchmarks make the reason obvious. On LiveCodeBench, V4-Pro scores 93.5, ahead of Gemini (91.7) and Claude Opus (88.8). On Codeforces — the live competitive programming rating — V4-Pro lands at 3206, a hair above GPT-5.4 (3168) and well above Gemini (3052). On agent tasks, DeepSeek’s own internal eval claims V4-Pro-Max “outperforms Claude Sonnet 4.5 and approaches the level of Opus 4.5,” which is the kind of language a Chinese lab does not use lightly.
The picture is not all clean wins. On SWE-bench Verified — multi-file software engineering with real GitHub issues — V4-Pro lands at 80.6%, marginally behind Claude Opus 4.6 at 80.8%. Effectively a tie, but Claude is still the king of long-horizon multi-file refactors. On reasoning benchmarks, V4-Pro scores 8.17 against Claude Opus 4.6 standard at 8.18, then gets blown out by Claude Opus 4.6 Thinking at 8.82. The thinking-mode gap is real.
The honest synthesis: DeepSeek V4-Pro is roughly 3-6 months behind frontier on pure capability, ahead of frontier on coding speed and Codeforces, and operating in a different universe on price. That’s a coherent strategic position. It is also a gift to anyone building products on top of LLMs.
The pricing humiliation
This is the part Western labs need to read twice.
| Model | Input ($/M tokens) | Output ($/M tokens) |
|---|---|---|
| DeepSeek V4-Flash | $0.14 | $0.28 |
| DeepSeek V4-Pro | $1.74 | $3.48 |
| Claude Opus 4.6 | ~$15 | ~$25 |
| GPT-5.5 Pro | ~$10 | ~$30 |
A million output tokens is roughly the size of an average novel. V4-Flash will write that for the price of a coffee that has gone cold. Claude will write the same novel for the price of a flight to Berlin. Both numbers are real, both APIs are public, both shipped on the same day in April.
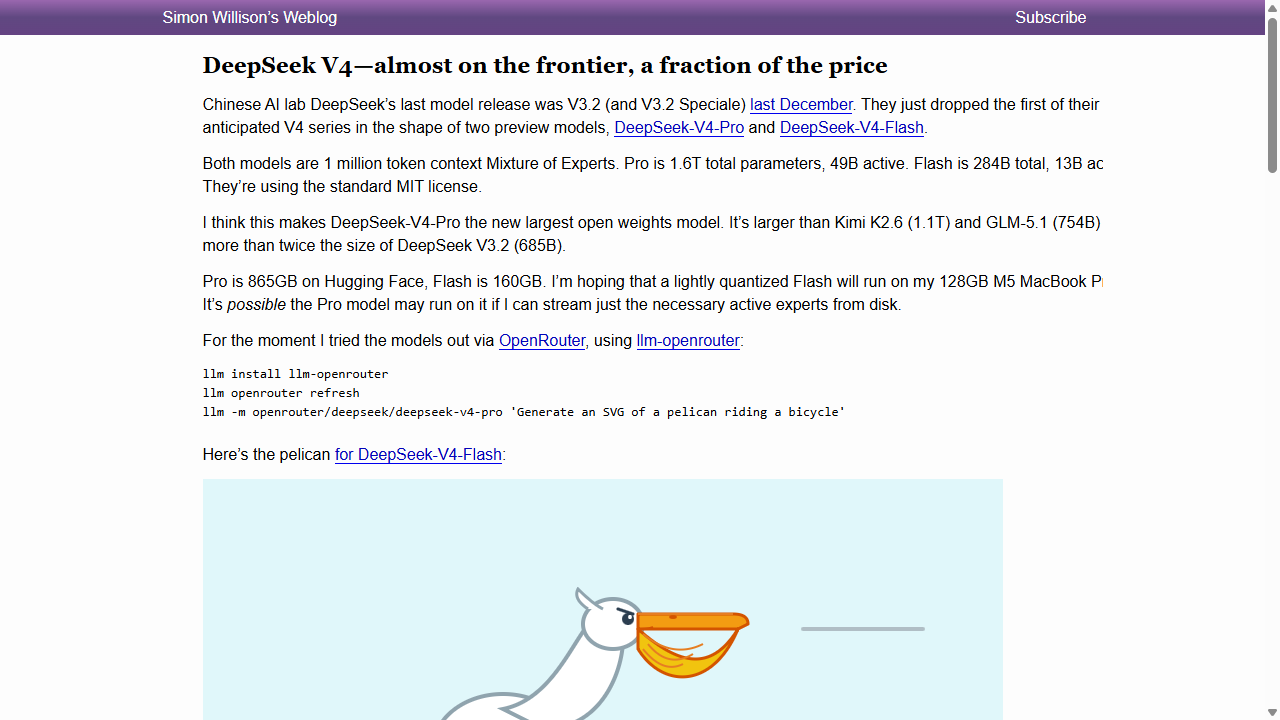
Simon Willison’s verdict, written within hours of the launch: “DeepSeek V4 — almost on the frontier, a fraction of the price.” He is being polite. The actual situation is that DeepSeek has demonstrated, for the second year running, that the cost-to-capability curve Western labs are pricing against is a curve they themselves invented and that nobody outside their billing system is required to respect.
The moat is a puddle
For two years the consensus story in Western AI has been that frontier models are expensive because they are hard. That training compute is gated, post-training is a craft, alignment is a moat. There has been a steady, cheerful narrative in podcast appearances and S-1-adjacent investor decks about how the leaders extend their lead each year and how the followers — DeepSeek, Mistral, Qwen, Kimi — are perpetually a generation behind, useful as commodity infrastructure but not for “real” frontier work.
What April 24 did is end that narrative as a defensible position.
DeepSeek V4-Pro is, by their own admission, behind frontier — by three to six months. It is also free to download, runs on Huawei chips, integrates with Chinese cloud stacks at a fraction of the inference cost, and ships a 1M context window that Claude doesn’t yet match. A three-to-six month gap that you ship for free, in MIT-licensed weights, is not a moat. It’s a reminder that everyone involved in this race is running on the same physics.
The implication for Western labs is uncomfortable. Anthropic is currently raising $40B from Google. OpenAI is at $25B run-rate revenue, reportedly prepping a public listing. Both companies’ valuations are predicated on a moat that DeepSeek just open-sourced an 89×-cheaper version of. Either Western labs find a real differentiator — agent capability, computer use, reliability at horizon — or the price floor on inference falls until subscription pricing stops covering compute.
The Blunt takeaway
I am not saying DeepSeek V4 is the best model. It isn’t, on the metrics where Claude and GPT-5.5 still lead. I am saying that the gap between best and good-enough is now the difference between $25 and $0.28, and a lot of products will pick the cheaper number.
If you build with LLMs — agent tools, copilots, content workflows, internal automations — you have a homework assignment this weekend. Wire DeepSeek V4-Flash into one of your pipelines. Run a few thousand calls. See what breaks. The cost is rounding-error and the lesson, whichever way it goes, is worth more than the inference bill.
If you sit in a Western AI lab pricing meeting, you also have a homework assignment. Open the V4 model card on Hugging Face. Read the benchmarks. Then explain, out loud, to your boss, why your output token costs $25.
My rating on this drop: Shut up and try it. Not because V4 is going to replace your frontier model in production — it probably won’t. But because the price floor in the LLM market changed last week and pretending otherwise is the kind of complacency that gets your company priced into a corner.
Disclaimer: BluntAI may earn affiliate commissions from links in this article. This never influences our reviews. We buy and test everything ourselves. Our opinions are brutally our own.