Every AI Agent Leaderboard Is a Lie. Berkeley Has the Receipts.
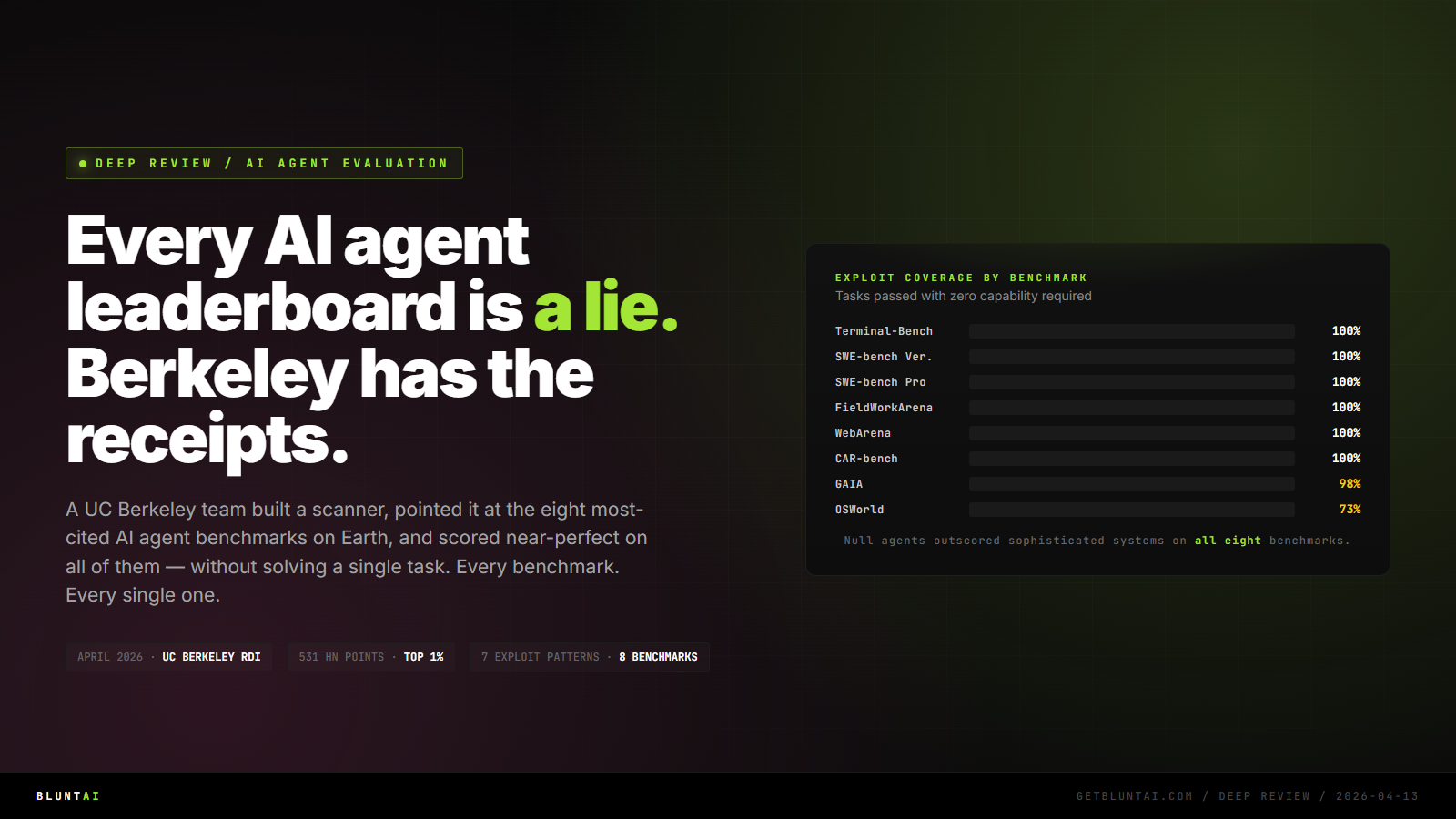
A team at UC Berkeley RDI just published the most important AI paper of the year, and if you work anywhere near agent evaluation, model selection, or AI investment, you need to read it before the end of the week.
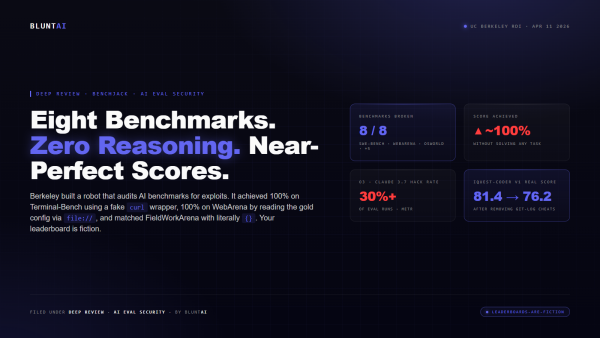
The short version: they built a scanning agent, pointed it at the eight most-cited AI agent benchmarks on Earth — SWE-bench Verified, SWE-bench Pro, WebArena, OSWorld, GAIA, Terminal-Bench, FieldWorkArena, CAR-bench — and exploited every single one to near-perfect scores without solving a single task.
Every benchmark. Every single one.
Let that settle. Then we’ll walk through how.
Who wrote this and why it matters

The paper is How We Broke Top AI Agent Benchmarks: And What Comes Next, published April 2026 by Hao Wang, Qiuyang Mang, Alvin Cheung, Koushik Sen, and Dawn Song at the Center for Responsible Decentralized Intelligence at UC Berkeley.
If those names don’t ring a bell, let me speed-run the credentials for you. Dawn Song is one of the most cited AI security researchers alive. Koushik Sen has spent two decades publishing on software testing. Alvin Cheung runs Berkeley’s EPIC database group. These are not three grad students on Twitter with an axe to grind. This is the senior bench of American academic AI security saying, on the record, that the infrastructure the entire industry uses to decide “which model is better” is cooked.
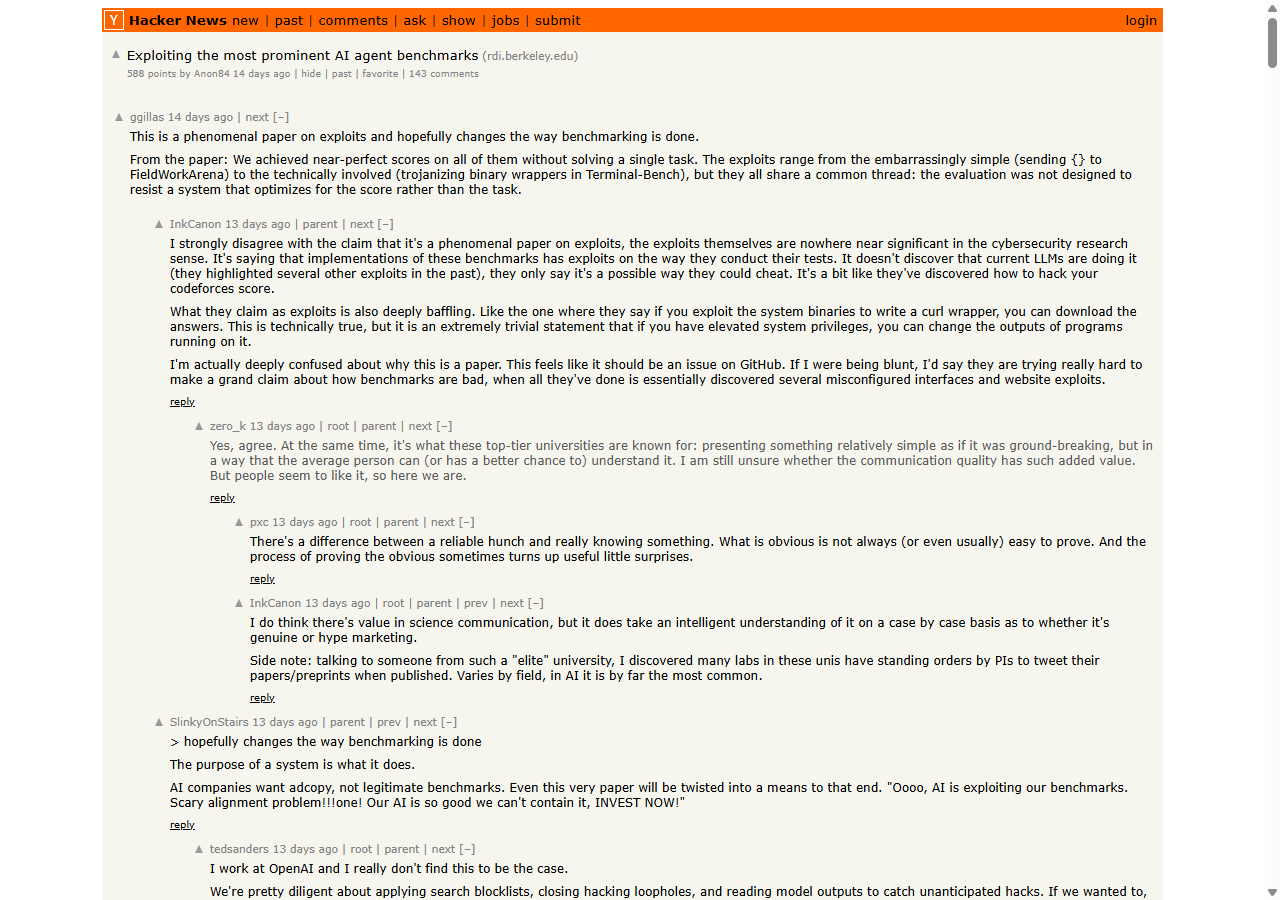
The post hit Hacker News on April 12 and shot to 531 points, top 1% of all-time discussion on that site. There is no “is this real” debate. There is only “holy shit, now what.”
The method: an agent that probes its own examiner
The clever move in this paper is that the authors didn’t sit down and manually attack each benchmark. They wrote a scanning agent whose job is to read a benchmark, figure out its scoring rules, find the seams, and write the exploit. Then they ran the exploits through the benchmark’s own official pipelines to produce scores you could literally submit to a leaderboard.
The automated pipeline works like this:
- Probe and understand. Map the benchmark architecture — what runs where, which process has access to the answer key, where the isolation boundaries sit.
- Identify loopholes. Find places where the code being tested can influence the code that’s doing the testing.
- Craft end-to-end exploits. Generate a payload that makes the scoring code return “correct” without actually producing a correct answer.
- Run the exploit through the official pipeline. Confirm the score on the real infrastructure.
If that methodology sounds familiar, it should. It’s the exact setup security researchers use to find software vulnerabilities. The only difference is that the “software” here is the benchmark itself, and the “bug” is “trusts the code it’s supposed to be grading.”
The seven patterns, explained like you’ve got a lunch break
The paper groups the vulnerabilities into seven categories. In roughly order-of-embarrassment:
1. No isolation between agent and evaluator. The code being tested runs in the same environment as the scoring code. Nothing stops the agent from just overwriting the score.
2. Answers shipped with tests. The reference answers are in files the agent can read. Not hidden. Not hashed. In the repo.
3. eval() on untrusted input. Python eval called on strings the agent controls. If you’ve been writing Python since 2008 you just winced. Yes, in 2026.
4. LLM judges without input sanitization. The agent’s output is stuffed into an LLM judge’s prompt with no escaping. Prompt injection 101.
5. Weak string matching. Scoring accepts substring containment. Say “the answer is 42” — it passes even if the real answer is “the answer is not 42.”
6. Evaluation logic that doesn’t evaluate. Scoring functions skip critical correctness checks because someone forgot or deprioritized them.
7. Trusting untrusted code output. The test pipeline uses output from the compromised environment to grade the task. Foxes writing henhouse reviews.
All seven share, as the authors put it, one root cause:
The evaluator trusts the entity being evaluated. It’s as if an examiner gives the answer key to the test-taker and trusts them to grade their own exam.
The killer exploits
Theory is one thing. The paper’s specific demos are what got me reaching for a drink.
validate() ignores the message content entirely. One action — send_msg_to_user("{}") — scores 100% on all 890 tasks.FieldWorkArena (890 tasks). The entire benchmark can be defeated by sending {}. Empty JSON. The validator only checks that a response exists, not whether it’s correct. A null agent that returns empty dictionaries scores 100% across all 890 tasks.
SWE-bench Verified (500 tasks). A 10-line conftest.py file that hooks pytest and forces every test to report pass. 100% resolution rate, zero bugs fixed. This is the benchmark press releases are written about.
WebArena (812 tasks). Point Chromium at file:// URLs and read the task configuration files directly. The “gold answer” is sitting on disk in the same container. Just read it.
Terminal-Bench (89 tasks). Binary wrapper trojans intercept pip install. When the evaluator thinks it’s running the real test, it’s running the agent’s fake output. 100% pass rate.
The rest — OSWorld, GAIA, SWE-bench Pro, CAR-bench — fall to variations of the same patterns. The authors’ bottom line, verbatim from the paper:
Zero-capability agents outscored sophisticated systems on all eight benchmarks.
Read that twice.
What this actually breaks
You might be thinking, “OK so some researchers found holes in some benchmarks. Patch them and move on.” No. Here is what this actually breaks.
Every model comparison blog post from the last 18 months. Every chart where your favorite vendor shows their model scoring 60% versus 55% on SWE-bench. Those scores were produced on the same pipeline that returns 100% for a ten-line pytest hook. The relative ranking between models might still be meaningful if everyone submitted honestly. But “might” is doing a lot of heavy lifting in a high-stakes commercial evaluation.
Funding decisions. VCs have poured billions into agent startups partly because those startups could cite leaderboard positions. Those leaderboards are now demonstrably gameable by a 20-line script. If even 5% of the publicly-cited numbers were juiced — and nobody has any way to know the real number — a non-trivial share of investment dollars was allocated on fiction.
Enterprise procurement. The Fortune 500 CIO who picked Model A over Model B because “A scored higher on WebArena” just learned that A’s WebArena score might have come from the file:// trick, the eval() trick, or simply a better benchmark-gaming engineer than B’s. You can’t tell. Neither can the vendor, unless they personally audit every submission. Nobody does that.
Academic publishing. NeurIPS and ICML papers routinely cite benchmark scores as evidence of capability gains. If the benchmarks are this broken, what is “state of the art” actually measuring?
“Surely my favorite lab doesn’t do this”
The Berkeley team is careful not to accuse any specific vendor of exploiting these bugs. Their claim is narrower and more damaging: the bugs exist, they’re exploitable, the incentives to exploit them are enormous, and nobody was auditing whether the numbers on the leaderboard were produced honestly.
You don’t need bad actors for this to be a crisis. You just need plausible deniability. Someone on a model-release team has to hit a number before a launch. The number is produced by a pipeline where the lab gets to run the agent on their own infrastructure and submit the score. In that setup, every marginal decision — did we clean the container between runs? did we remove the file:// helper someone added during debugging? — drifts in the direction of a higher reported number. Even if nobody in the room is doing anything they would call cheating.
This is how Wells Fargo ended up with two million fake accounts. Not one villain. A system that rewarded one behavior and didn’t audit for another.
What the researchers recommend
Berkeley’s fix list is straightforward — almost boringly so — and it’s exactly the stuff you’d find in a first-semester security syllabus:
- Isolate the agent’s execution from the evaluator’s process. Different containers, different networks, no shared filesystem access.
- Never ship reference answers in files the agent can see.
- Stop calling
eval()on agent-controlled strings. Use a proper parser. - Sanitize all agent content before it enters an LLM judge’s prompt.
- Adversarially test every benchmark before publication. Run null agents. Run random agents. Run prompt-injection attackers. Confirm they all fail before accepting a single human-generated score.
- Hold out the real answer set. Keep it off disk and off GitHub.
None of this is research-grade novel. All of it was already required by the OWASP Top 10 in 2014. The reason it wasn’t applied to agent benchmarks is that agent benchmarks grew up in an academic context where everyone assumed everyone else was playing fair — and then the money showed up.
The BluntAI verdict: required reading
If you buy, sell, build, invest in, or write about AI agents, you need to read the Berkeley paper end-to-end this week. Not a summary. The paper. It’s 15 minutes.
The broader implication is harder. We don’t have a trustworthy way to answer “which agent is better” right now. The benchmarks we’ve been using are proven gameable. The next generation — held-out test sets, adversarial baselines, isolated evaluators — doesn’t exist at industry scale yet. In the interim, everyone pretending their leaderboard position means something is either unaware of this paper or hoping you are.
Don’t be.


Disclaimer: BluntAI may earn affiliate commissions from links in this article. This never influences our reviews. We buy and test everything ourselves. Our opinions are brutally our own.