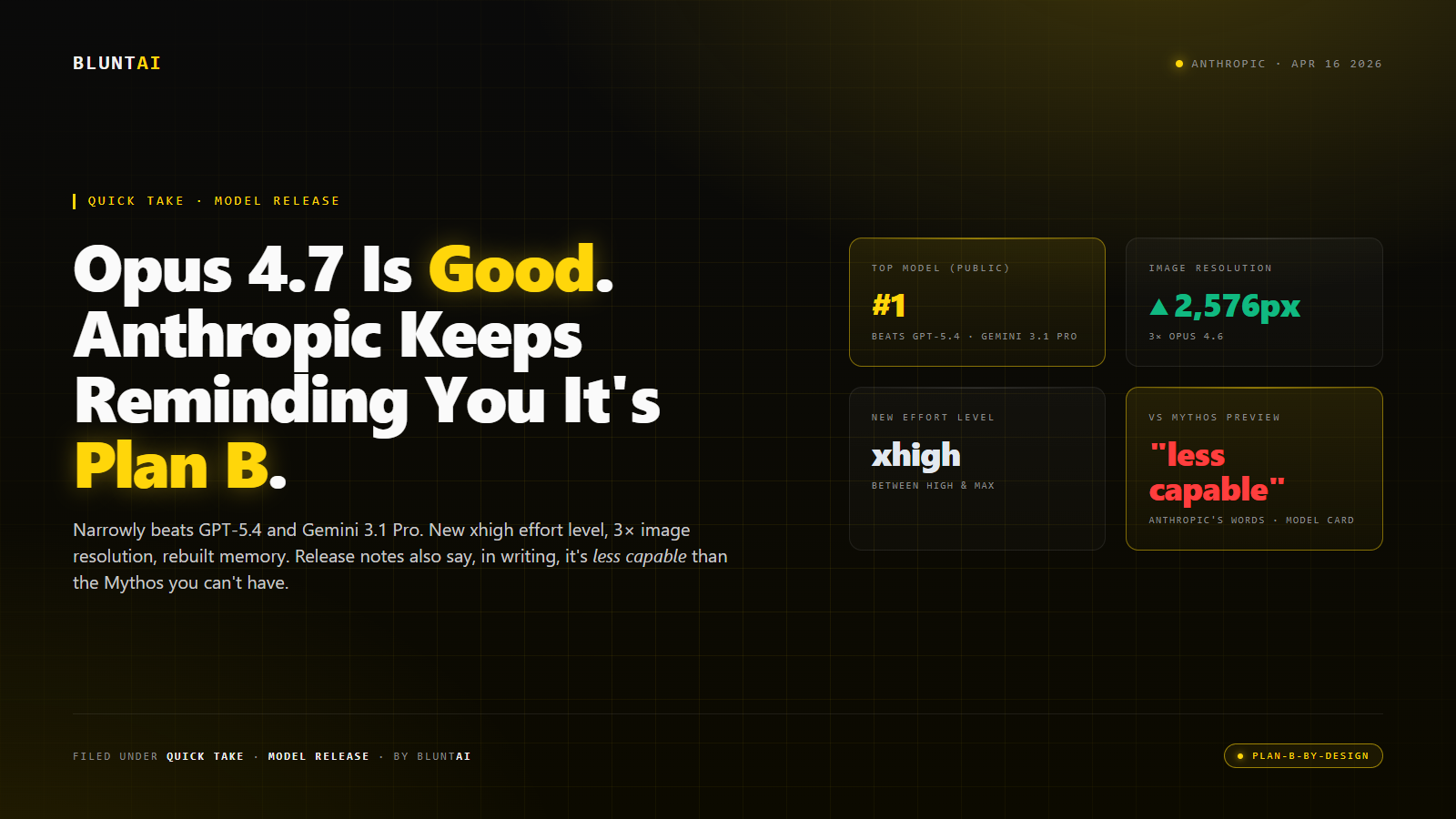
Claude Opus 4.7 Is Good. Anthropic Keeps Reminding You It’s Plan B.
Anthropic dropped Claude Opus 4.7 on Thursday, April 16, 2026. By the time I finished reading the release notes and the model card, I had the same thought I suspect everybody who writes about Anthropic is going to have for the next few months: this is a genuinely strong model, and the company cannot quite bring itself to sell it without reminding you that there is a better one behind the velvet rope.
Let me walk you through what 4.7 actually does, then the asterisk Anthropic put on the whole thing.
The good part
On the benchmarks the industry uses to rank frontier models, 4.7 narrowly retakes the top spot among publicly available LLMs — beating OpenAI’s GPT-5.4 and Google’s Gemini 3.1 Pro on agentic coding, scaled tool use, agentic computer use, and financial analysis. Not by a landslide. By the polite, professional margins that are the norm at the current top of the leaderboard. But enough that the “most powerful generally available” crown sits at Anthropic this month.
Three upgrades are doing the work. First, the model can look at images at up to 2,576 pixels on the long edge — roughly three times the pixel count the previous Claudes could handle. In practice this means dense screenshots, complex diagrams, and high-resolution photos become legible rather than lossy, which, if you’ve ever tried to debug a UI mockup with an AI that saw your screen as a 512-pixel blur, is a substantive quality-of-life change.
Second, there’s a new effort level called xhigh, slotted in between “high” and “max.” It’s a knob you get to turn when you’re trying to trade reasoning depth against latency on a hard problem. Anthropic’s recommendation for coding and agentic tasks is to start at high or xhigh. The existence of this knob says something about what they’ve been hearing from developers: people wanted a middle gear on the reasoning axis.
Third, and this is the one that matters most for anyone building agents: the memory system has been rebuilt around a file-system-style approach that lets the model retain and reference notes across tasks, instead of forcing you to re-inject context on every call. This is the feature that will quietly eat the most of your token budget and the most of your frustration, depending on your workload.
Pricing is unchanged from 4.6. A new tokenizer means the actual token counts per request can drift up or down depending on the input, but the headline cost per token is the same. Available everywhere Anthropic ships: claude.ai, API, Bedrock, Vertex, Foundry, GitHub Copilot.
The asterisk
Here is where it gets interesting.
Embedded in the release notes, with a level of candor that the industry is not accustomed to seeing, Anthropic states that Opus 4.7 is “less broadly capable” than Claude Mythos Preview. The same Mythos Preview that Anthropic confirmed in early April exists, confirmed is more capable than anything else they have ever built, confirmed has been handed to a dozen launch partners under the “Project Glasswing” program, and confirmed — this is the part that should not go unremarked — will not be made generally available.
So when you read the 4.7 press release, you are reading a release for a model that the company building it has on record told you is the backup plan.
That’s an unusual posture. Most companies launching a new flagship go out of their way to not mention any internal model that happens to be more capable. Anthropic is, for reasons that are partly safety-theatrical and partly genuinely worth respecting, being transparent about the tier split: there is the model you can buy, and there is the model they’ve decided you cannot buy, and those two things are not the same.
The practical effect is that 4.7 is being positioned, in Anthropic’s own framing, as a testing ground for the cybersecurity safeguards they will eventually need if they ever decide to ship something Mythos-class to the public. In other words: the point of shipping this model is not just to give you a better daily driver, it is also to field-test the constraints the company wants wrapped around future releases. You are part of the dry run.
I don’t actually hate that framing. It’s honest. But it does mean that when you sit down with 4.7, you are sitting down with the most capable model Anthropic felt comfortable releasing, not the most capable model Anthropic has built. Those are different products.

What to actually do with it
If you’re a Claude Pro subscriber or an API customer, 4.7 is the default recommendation for anything involving:
- Large multi-step agentic workflows — the long-horizon autonomy improvements are real and you’ll feel them on tasks that span more than a couple of tool calls.
- Dense visual input — screenshots of dashboards, annotated diagrams, code in IDEs, photo-heavy PDFs. This is where the 2,576-pixel vision upgrade earns its keep.
- Financial and legal analysis — Anthropic is claiming state-of-the-art on GDPval-AA for finance and law. Early external testers are corroborating that the model is genuinely good at these professional domains.
- UI and design work — this is the surprise of the release. Early users report that 4.7’s design taste is noticeably better than any prior Claude. Triple Whale’s CEO said its choices were “genuinely surprising — it makes choices I’d actually ship.” That’s the kind of quote you don’t see in an LLM launch very often.
Where you should be more careful:
- Prompt migration — 4.7 follows instructions more literally than 4.6. If you have prompts tuned for the previous model’s interpretive style, you will need to rewrite them. Anthropic explicitly warns about this.
- Token accounting — new tokenizer, more thinking at higher effort levels. Budget for your bill to be 10-20% higher on the same workload before you’ve tuned anything.
- Edge-case safety — Anthropic disclosed a “modest weakness” on harm-reduction advice around controlled substances compared to 4.6. If that’s load-bearing for your use case, read the model card.
The BluntAI verdict
For most of the world, 4.7 is a Solid, no drama upgrade. Ship it. If you’re on 4.6, the migration cost is real but not insane, and the benchmark delta is worth it. If you’re on a competitor’s flagship, this is the strongest argument Claude has made for itself in a quarter.
But I am not going to let the release-note phrasing slide: we are in a world where the most capable model at the world’s second-largest AI lab exists, is confirmed, and is deliberately not being offered to you. Opus 4.7 is the best version of the model they’ll let you rent. That is not the same thing as the best version they have. Keep that in your head when you decide which infrastructure to bet on. The answer isn’t “don’t bet on Anthropic” — the answer is “understand which tier of their catalog you’re actually buying.”
Sources
- Anthropic — Introducing Claude Opus 4.7 (April 16, 2026)
- VentureBeat — Anthropic releases Claude Opus 4.7, narrowly retaking lead for most powerful generally available LLM (Carl Franzen)
- The New Stack — Claude Opus 4.7 arrives with better vision, memory, and instruction-following
- Axios — Anthropic releases Claude Opus 4.7, concedes it trails unreleased Mythos
- SiliconANGLE — Anthropic launches Claude Opus 4.7 with coding, visual reasoning improvements
All opinions expressed on BluntAI are editorial opinions based on publicly available information and personal testing. We may earn affiliate commissions from links on this site.

Disclaimer: BluntAI may earn affiliate commissions from links in this article. This never influences our reviews. We buy and test everything ourselves. Our opinions are brutally our own.