
MegaTrain trains 100B models on one GPU. And 1.5TB of host RAM.
The headline is spectacular: “MegaTrain: Full Precision Training of 100B+ Parameter LLMs on a Single GPU.” Hacker News ate it up — 324 upvotes, 57 comments, the kind of front-page run that makes researchers feel famous for a weekend. And the paper is real. The arxiv submission from Zhengqing Yuan and co-authors drops today, the GitHub repo is up at 423 stars, and the system does what it says on the tin.
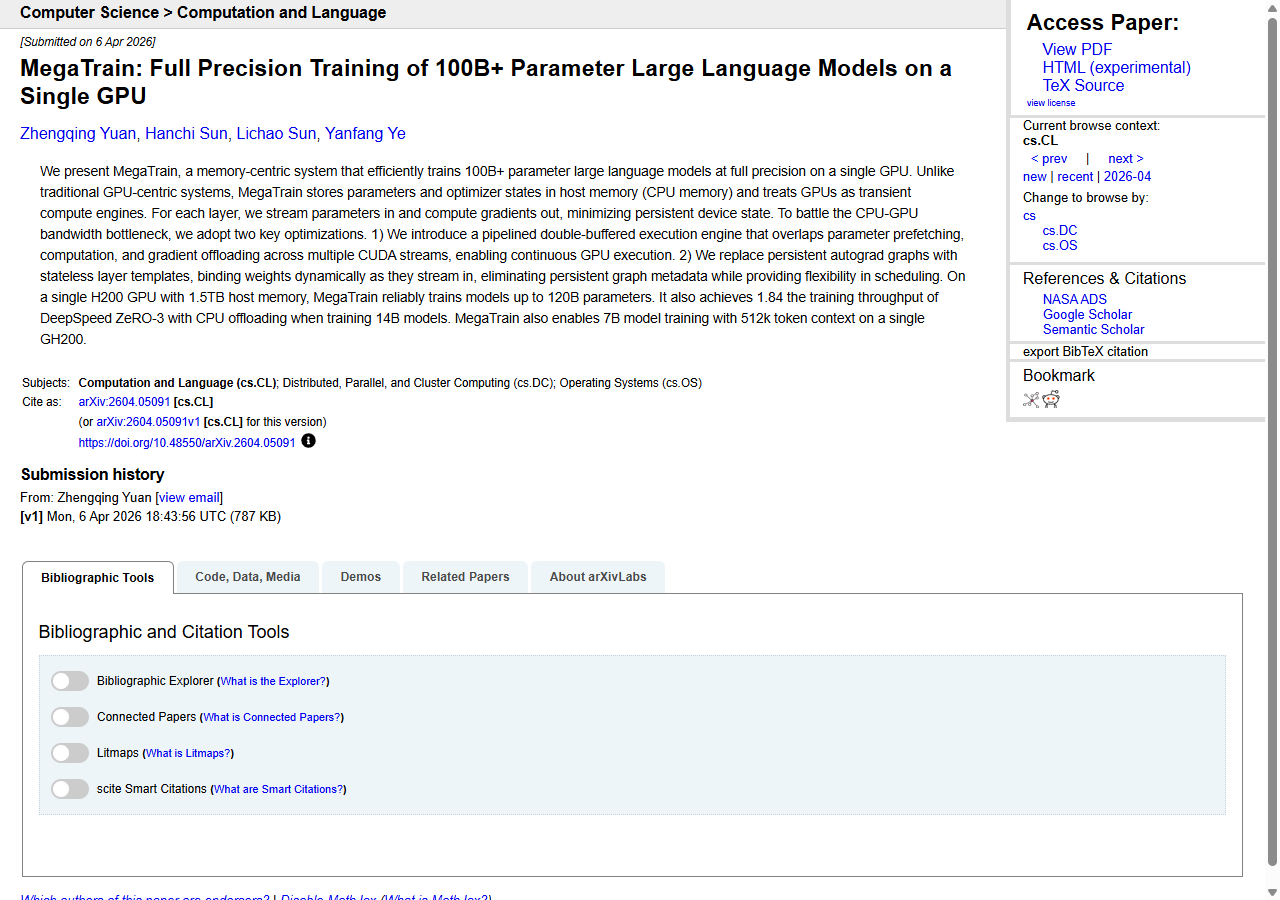
Now let’s read the abstract carefully. “A single H200 GPU with 1.5TB host memory.” That second clause is doing all the work. A workstation that can hold 1.5 terabytes of DDR5 is not a laptop, not a 3090 build, not something a grad student expenses on a research grant. You’re looking at a dual-socket Xeon or EPYC chassis north of forty grand before you even slot the H200 in. “Democratizing 100B training” — sure, if your definition of democracy includes a six-figure server room.
The second problem is throughput. The paper reports 341 tokens/sec on a 14B model, and claims 1.84× the training throughput of DeepSpeed ZeRO-3 with CPU offloading. Fair enough — until you read the top-voted HN comment from kouteiheika, who’s been quietly doing this exact thing for months:
“They got 341 tok/s for a 14B model on a single 3090 while with my method I was getting ~1k tok/s on a single 4090; that’s still very slow.”
kouteiheika, HN #47690851
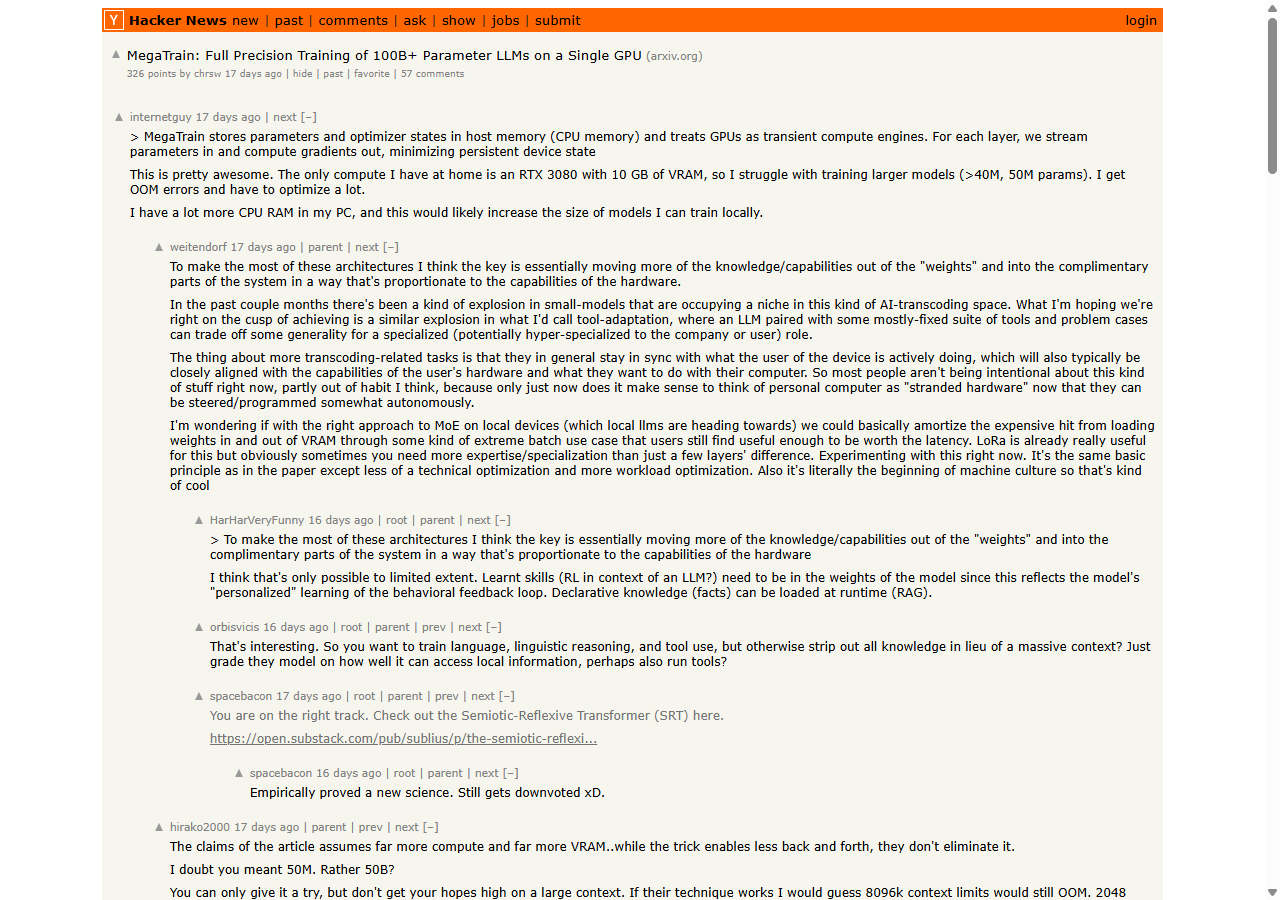
So a random practitioner with a consumer 4090 is 3× faster than the headline benchmark. Not because MegaTrain is bad — but because “fits on one GPU” is cheap and “fast enough to actually iterate” is the real bar.
Where MegaTrain does earn its keep: labs with big-DRAM workstations who need full-precision fine-tuning on models that would otherwise require a multi-GPU cluster. Low-sample regimes. Teaching environments. Any setting where “slow but runs” beats “fast but needs 8 H100s.” That niche is real. It’s just not the whole front page of HN.
The hardware tax nobody priced
Let’s actually run the numbers MegaTrain glosses over. A workstation that holds 1.5TB of DDR5 ECC at the speeds the paper assumes is a dual-socket EPYC 9004 or 9005 board, somewhere in the $8,000–$15,000 range just for memory, plus motherboard, CPUs, PSU, and chassis. Add the H200, plus an enterprise NVMe pool for offload spillover, and the “single-GPU” rig clears $70,000 before you spin a single epoch. That is not a research grant outlier. That is a small server budget.
Compare with the cloud alternative. Modal, RunPod, and Lambda all rent 8×H100 nodes by the hour. At $2–$3/GPU/hour, a week of pre-training a 70B model lands around $4K-$8K of compute — less than the DDR5 alone for the MegaTrain rig. “Single GPU” only wins when sustained utilization is high enough to amortize the workstation. For the median fine-tune, it isn’t.
Where this actually matters
None of this kills the paper. It just relocates the audience. MegaTrain isn’t for the indie dev with a 4090 and an empire dream — that person is already running a QLoRA fine-tune via Unsloth and shipping. MegaTrain is for the corporate research lab that has a couple of beefy on-prem boxes sitting idle, can’t (or won’t) push training data to a public cloud, and needs full-precision fine-tuning on a model that wouldn’t fit otherwise. That is a real, legitimate, narrow niche — and a very different story than the one HN voted into the front page.
Call it what it is: a legitimate systems paper wearing a clickbait title. Read the abstract. Skip the second clause at your peril.


Disclaimer: BluntAI may earn affiliate commissions from links in this article. This never influences our reviews. We buy and test everything ourselves. Our opinions are brutally our own.