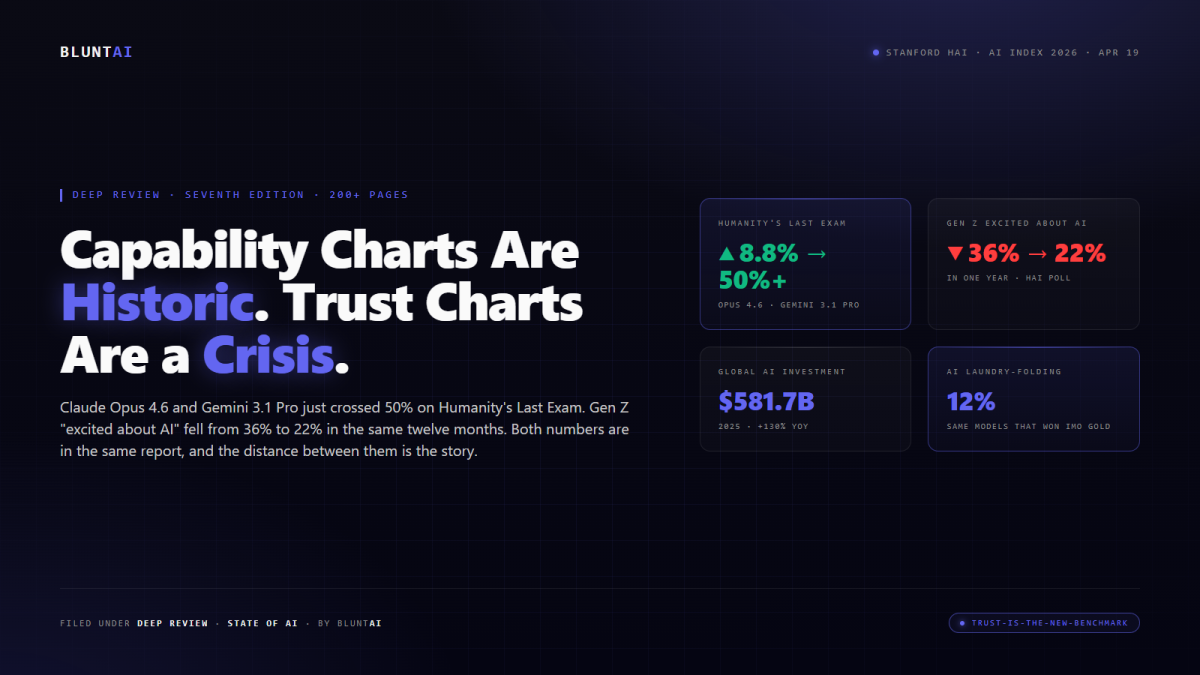
Stanford’s 2026 AI Index: The Capability Charts Are Historic. The Trust Charts Are a Crisis.
Stanford HAI released the seventh edition of its AI Index Report today. It is, as usual, a two-hundred-page brick of charts that you can…
Latest Reviews
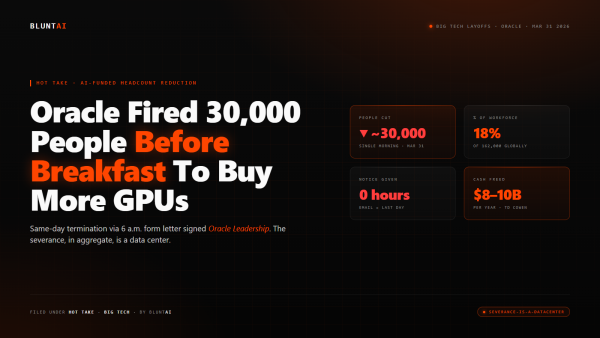
Oracle Fired 30,000 People Before Breakfast To Buy More GPUs
The email hit inboxes at 6 a.m. local time. United States, India, Canada, Mexico — whatever side of the planet you woke up on,…
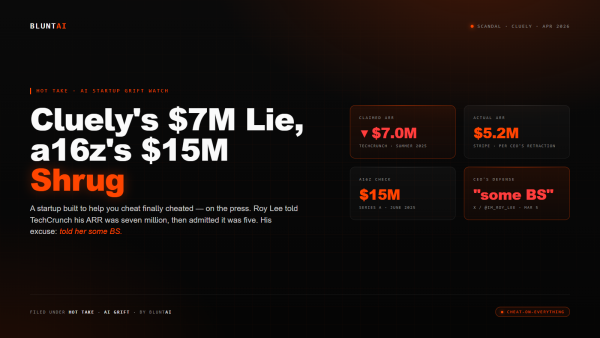
Cluely’s $7M Lie, a16z’s $15M Shrug, and the Cheating Startup That Finally Cheated on the Press
Here is the part of the Cluely story that every venture capitalist is going to pretend they didn’t notice. In April 2025, a twenty-one-year-old…

Gas Town Uses Your Claude Credits to Fix Its Own Bugs. Nobody Told You.
Uninstalled in 10 minutes Steve Yegge’s Gas Town — the multi-agent workspace manager that’s been picking up steam since January — just got caught…
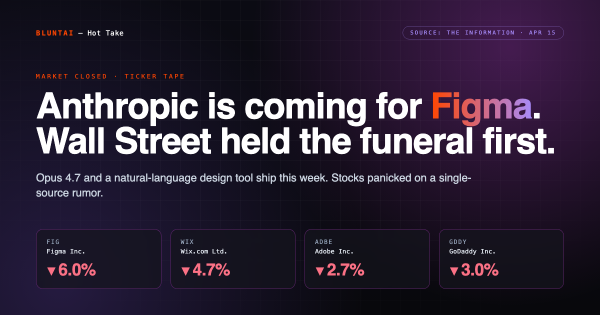
Anthropic’s Next Model Drops This Week. So Does Their Figma Killer. Wall Street Priced In the Funeral Early.
Anthropic is launching Claude Opus 4.7 this week. And, in the same breath, a design tool that turns plain English into websites, landing pages,…

MegaTrain trains 100B models on one GPU. And 1.5TB of host RAM.
The viral arxiv paper promising 100B parameter training on a single GPU buries the real price tag: a 1.5TB-RAM workstation, a 341 tok/s ceiling, and a random HN commenter getting 3x the speed on a consumer 4090.
30K Stars for a Claude Code Apology Letter
GitHub's hottest repo this week is a 65-line CLAUDE.md patching Claude Code's defaults. 30K stars overnight. The viral repo is a referendum on bad defaults, not a compliment.

Stanford just dropped 400 pages of AI receipts. Here’s what actually matters.
The 2026 AI Index is out. Inference costs collapsed 280x in 18 months, GPUs hit 17.1 million globally, data centers are pulling 29.6 GW, and China closed the gap to 2.7 percent. Blunt read of the numbers everyone will misquote.
Anthropic Leaked Claude Code, Then DMCA’d the Internet
A missing .npmignore shipped 513,000 lines of closed-source TypeScript to npm. The cleanup nuked 8,100 GitHub repos, including forks of Anthropic's own public repos. A week of ops own goals, receipts inside.
Every AI Agent Leaderboard Is a Lie. Berkeley Has the Receipts.
UC Berkeley scored near-perfect on eight of the most-cited AI agent benchmarks without solving a single task. SWE-bench, WebArena, OSWorld, GAIA, Terminal-Bench, FieldWorkArena, CAR-bench, SWE-bench Pro — all gameable. Here's how and what to do.